python (+ linux)でCMを検出して遊んでみる part1
普段はlinuxでavisynth + joinlogoscp + x265でエンコードをしていますが
cmカットってどんなんなんだろう?って思って色々試行錯誤してみました。
はじめに
・完全に興味本位で遊んでるので自己責任でお願いします
・中の人はプログラミングとかpcには無関係なお仕事の人です。ガバガバです。
・視覚的には悪くない?!
・概ね出来上がってるけど未完成です。
・ガバガバです(2回目)
方針
- JLSと同じようにロゴ方面と無音方面とシーンカットを調べてみる。
- できるだけavisynthとかexeを使わない(今回はpythonとffmpegだけです)
参考にさせていただいたサイト
貧者のcomskip (1) – パラメータ多すぎてわかんねえ – ぽこにっき
https://rikipoco.hatenadiary.org/entry/20180916/1537064561
Python+OpenCVでアニメのカット検出
https://nixeneko.hatenablog.com/entry/2017/09/07/000000
結果 サンプルA + 解説
元ファイル:26分59秒
正しい結果:"Trim(3,20412) ++ Trim(23110,45406) ++Trim(48105,48253)"
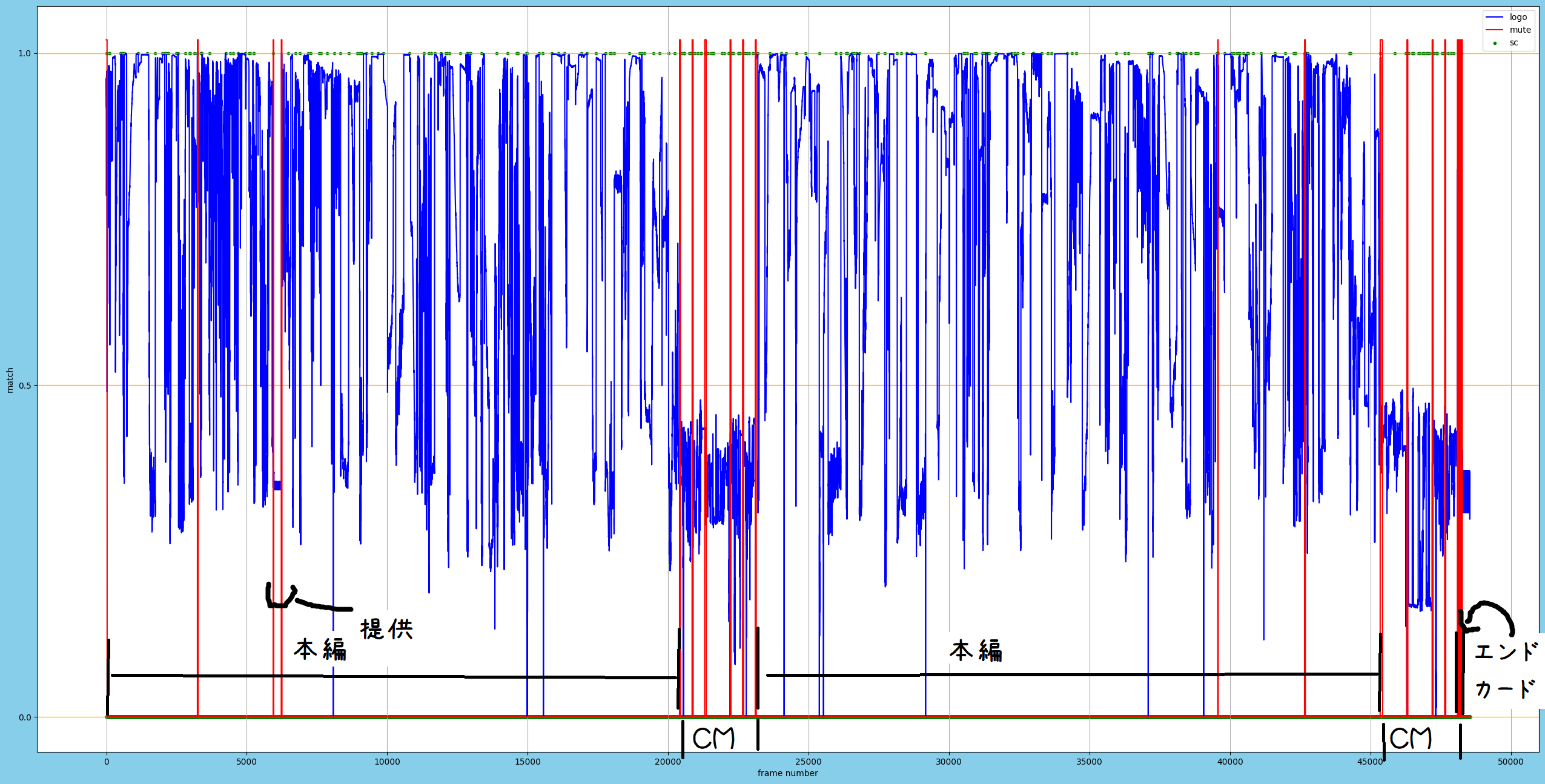
表の見方
x軸:フレーム
y軸:ロゴ検出(目安 0.6以上:目視可程度 0.85以上:はっきりとみえる)
青:ロゴ検出類似度
赤:無音検出部分(y数値は関係ない。拡大すると∏の形状になってます。下の拡大図を参照)
緑:シーンチェンジ検出部分(y数値は関係ない)

↑上の画像をさらに拡大して横に伸ばしたもの。
結果 サンプルB
元ファイル:26分59秒
正しい結果:"Trim(23,4971) ++ Trim(6771,25530) ++ Trim(27330,46300) ++ Trim(48099,48248)"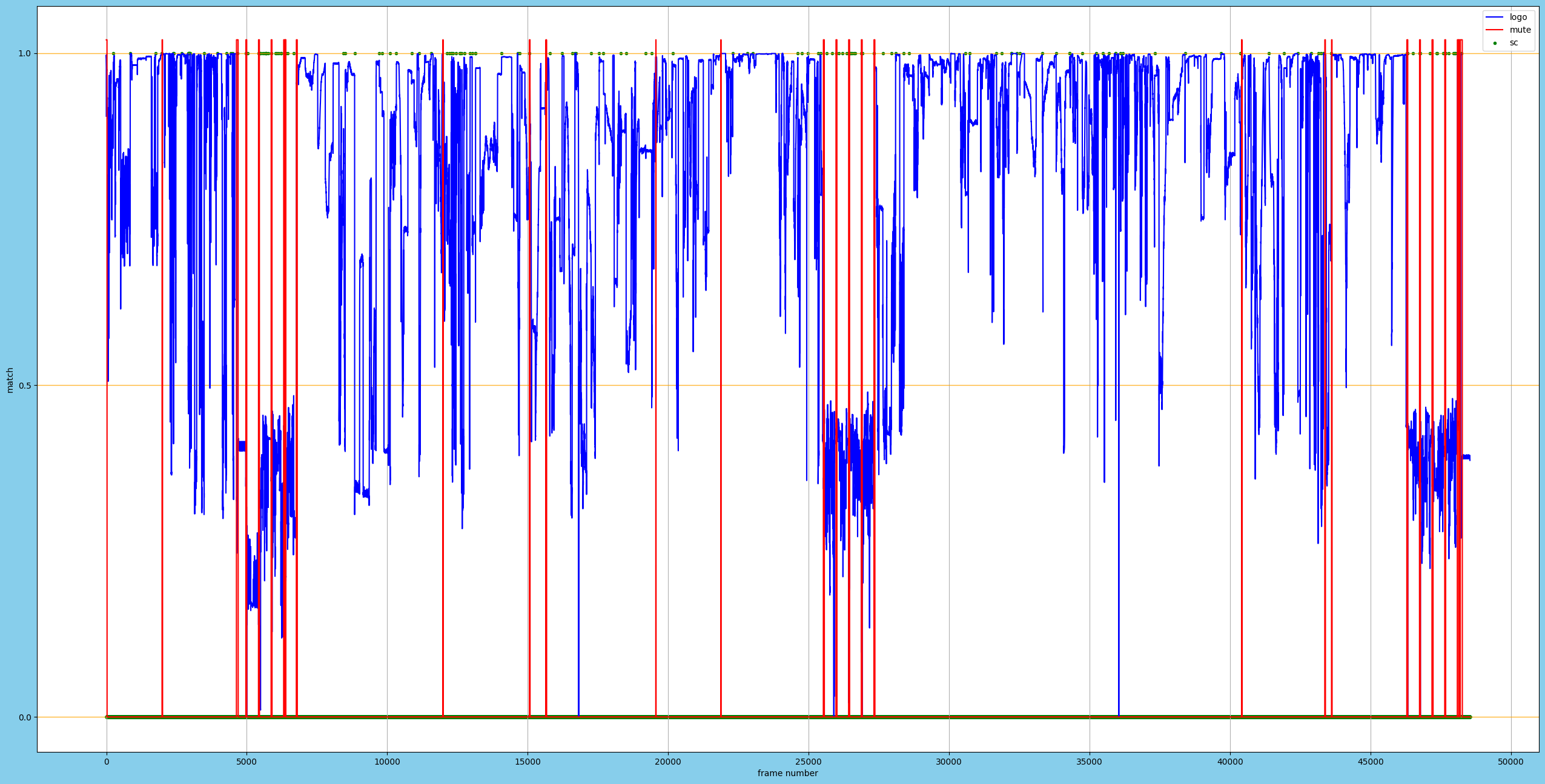
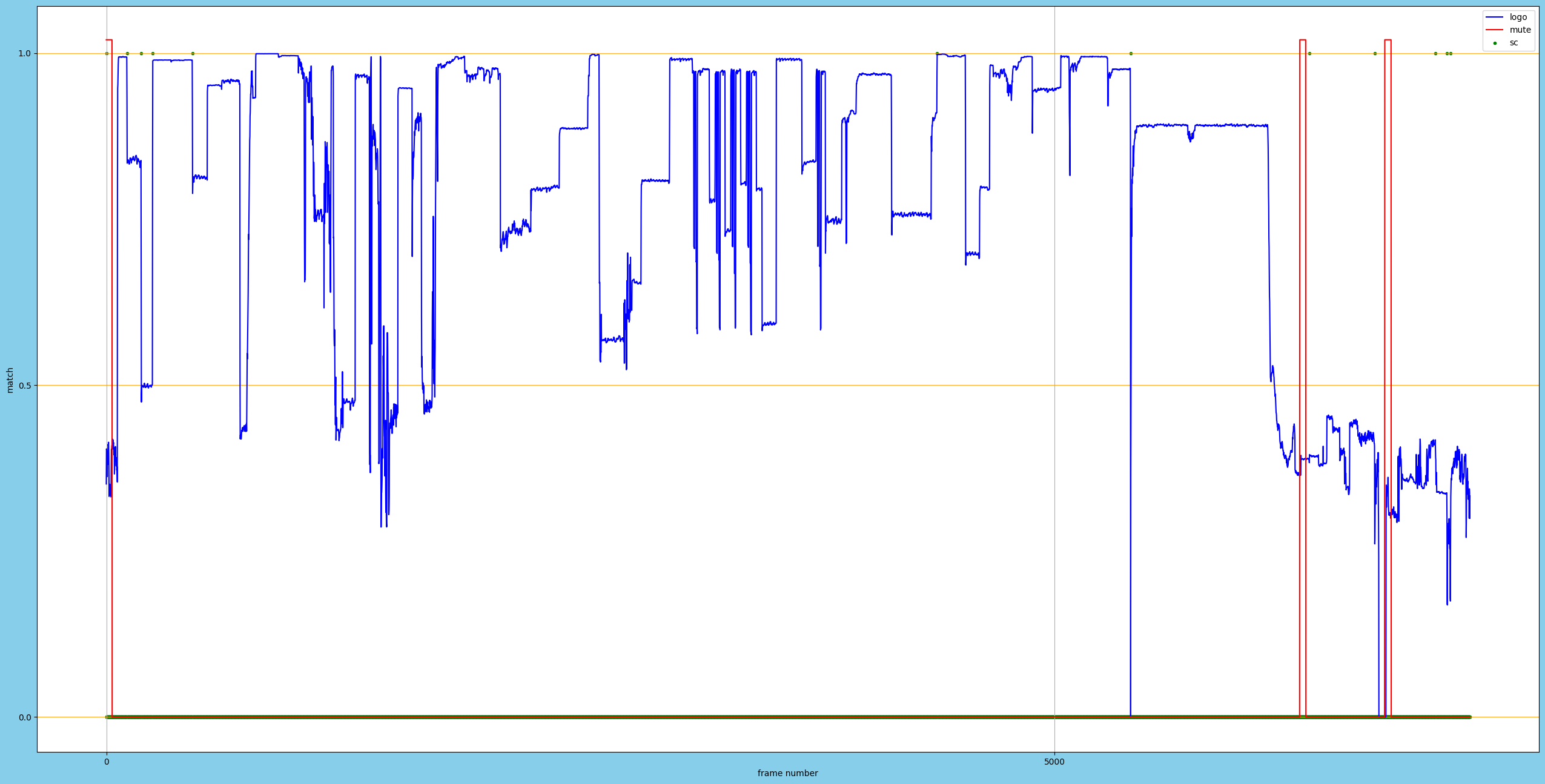
結果 サンプルC
元ファイル:3分59秒
正しい結果:"Trim(7,6299)"
ベンチ、実行速度
古いcpu Xeon E3-1265L V2 + ubuntu 18,04でだいたい340FPSです。
HDD(I/O)よりcpuがネックになっています。
回避方法が分かりませんが、お尻のGOPだけが正常に読めません。
残念なソースコード
プログラミング知らないので色々残念です。
opencvの動画読み込みは非常に遅いためn分割してます。
現状ではhddよりcpuがネックになってます。
・Queue
dequeも試しましたが1割ほど速くなりますが非常に不安定になったのでやめました。
キューに渡す回数を最低限にして、渡すサイズを小さくするのが今のところ一番良かったです(putとかappendは重いらしい?)
・問題点,1
動画の最後のgopがうまく読み込めないことが多く
適当な処理です。あまり結果に関連しないので放置あります。
・シーンチェンジの存在意義
上記の画像をみたところシーンチェンジ検出に存在意義があるのかと言われると、エンドカード検出ぐらいにしかなさそう。
またそのうち追記します。
#!/usr/bin/python3
# -*- coding: utf_8" -*-
import os,sys,cv2,glob
import time,shutil,csv
import numpy as np
import matplotlib.pyplot as plt
import subprocess
from multiprocessing import Queue, Process
from pydub import AudioSegment
from pydub.silence import detect_silence
#---------------------------------------------
tmp_dir = str(r'/dev/shm/')
result_image_dir = str(r'/hdd_disk/')
cache_dir = str(r'/dev/shm/.Trash-1000/')
sc_log_path = tmp_dir + 'sc.csv'
logo_log_path = tmp_dir + 'logo.csv'
mute_log_path = tmp_dir + 'mute.csv'
#---------------------------------------------
for i in [cache_dir]:
if os.path.exists(i):
shutil.rmtree(i)
#二値化した画像のエッジ検出、今のところこれが一番良い
def pre_compare_images(f):
img_sobel_x2 = cv2.Sobel(f, cv2.CV_32F, 1, 0)
img_sobel_y2 = cv2.Sobel(f, cv2.CV_32F, 0, 1)
img_sobel_x2 = cv2.convertScaleAbs(img_sobel_x2)
img_sobel_y2 = cv2.convertScaleAbs(img_sobel_y2)
D1 = cv2.addWeighted(img_sobel_x2, 0.5, img_sobel_y2, 0.5, 0)
return D1
#input_dataのtemplate match 、今のところこれが一番良い
def compare_images(input_data, template_data):
result1 = cv2.matchTemplate(input_data, template_data, cv2.TM_CCORR_NORMED)
minVal1, maxVal1, minLoc1, maxLoc1 = cv2.minMaxLoc(result1)
return maxVal1
#動画読み出しのイテレーター
class MovieIter(object):
def __init__(self, moviefile, size=None, crop=None, gray=None, inter_method=cv2.INTER_LINEAR, set='0', end=None):
self.org = cv2.VideoCapture(moviefile)
self.framecnt = 0
self.size = size
self.crop = crop
self.set = int(set)
self.end = int(end)
self.gray = gray
self.count = int(self.org.get(cv2.CAP_PROP_FRAME_COUNT))
self.inter_method = inter_method
if self.set:
self.org.set(cv2.CAP_PROP_POS_FRAMES, self.set)
def __iter__(self):
return self
def __next__(self):
self.end_flg, self.frame = self.org.read()
if not self.end_flg:
raise StopIteration()
if self.end:
if self.set + self.framecnt == self.end:
raise StopIteration()
self.framecnt += 1
if self.gray:
self.frame = cv2.cvtColor(self.frame, cv2.COLOR_BGR2GRAY)
if self.crop:
self.frame = self.frame[self.crop[0]:self.crop[1], self.crop[2]:self.crop[3]]
if self.size:
self.frame = cv2.resize(
self.frame, self.size, interpolation=self.inter_method)
return self.frame
def __del__(self):
self.org.release()
#シーンチェンジの評価関数
def MAE(pic):
return np.mean(np.abs(pic))
#連番CSVの結合
def join_csv_files(sorted_csv_flists):
list = []
x = list.extend
for i in sorted_csv_flists:
with open(i) as f:
reader = csv.reader(f)
x([row for row in reader])
return list
#二次元リストをcsvに書き込む
def write_csv(file, lists):
if os.path.exists(file):
os.remove(file)
with open(file, 'w', newline='') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(lists)
return
class analyze_ts:
def __init__(self, a, b):
self.name = a
self.logo = b
cap = cv2.VideoCapture(self.name)
self.h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
cap.release()
# settings > logo detect range
height = 150 # logo height
width = 250 # logo width
mergin_from_top = 20
mergin_from_right = 50
self.logo_size = (width, height)
self.logo_location = (mergin_from_top, mergin_from_right)
# settings > scene change
self.sc_THRESH = 70
self.sc_picsize = (64 * 1, 36 * 1)
#settings > others
self.threads = 8
def detect_mute(self):
s1 = time.time()
sf = tmp_dir + 'output.wav'
if os.path.exists(sf):
os.remove(sf)
command1 = ['ffmpeg', '-i', self.name, '-codec:a', 'copy', sf]
devnull = open('/dev/null', 'w')
z1 = subprocess.Popen(command1, stdout=devnull, stderr=devnull)
result = z1.communicate()
sound = AudioSegment.from_wav(sf)
mute_list = detect_silence(
sound, min_silence_len=50, silence_thresh=-80)
new = []
max = 0
for i in mute_list:
start = i[0] * 30 / 1001
end = i[1] * 30 / 1001
new.append([int(start), int(end)])
our_list = []
for i in range(self.count):
find = 0
for j in new:
if i >= int(j[0]) and i <= int(j[1]):
find = 1
break
if find == 0:
our_list.append([i, 0])
else:
our_list.append([i, 1.02])
write_csv(mute_log_path, our_list)
s2 = time.time()
print('End > analyze audio , Time= {}sec'.format(int(s2 - s1)))
return
def read_video(self, rad, q):
mergin_from_top, mergin_from_right = self.logo_location
width, height = self.logo_size
top = mergin_from_top
bottom = mergin_from_top + height
left = self.w - mergin_from_right - width
right = self.w - mergin_from_right
s, e = rad
x = q.put
if s == 0:
k1 = np.zeros((*self.logo_size[::-1], 3))
k2 = np.zeros((*self.sc_picsize[::-1], 3))
x([k1, k2])
else:
s -= 1
for frame in MovieIter(self.name, set=s, end=e + 1):
t1 = frame[top:bottom, left:right]
t2 = cv2.resize(frame, (64, 36), cv2.INTER_AREA)
x([t1, t2])
return
def mt_f1(self, n, m, num):
rad = (n, m)
q = Queue(150)
logo_data = pre_compare_images(cv2.imread(self.logo, 0))
pp1 = Process(target=self.__class__.read_video, args=(self, rad, q))
pp1.start()
my_cnt = n
empty = 0
result_logo, result_sc = [], []
while (q.empty()):
time.sleep(0.1)
first_frame = q.get()
c_frame_4logo, c_frame_4sc = first_frame
ap1 = result_logo.append
ap2 = result_sc.append
while (empty < 3 * 10):
if not q.empty():
de = q.get()
# detect_logo
p_frame_4logo, c_frame_4logo = c_frame_4logo, de[0]
p_frame_4sc, c_frame_4sc = c_frame_4sc, de[1]
inter = np.empty((*self.logo_size[::-1], 3), dtype=np.float32)
inter[1::2] = p_frame_4logo[1::2]
inter[0::2] = c_frame_4logo[0::2]
inter = cv2.cvtColor(inter, cv2.COLOR_BGR2GRAY)
frame_data = pre_compare_images(inter)
score = compare_images(frame_data, logo_data)
ap1([my_cnt, score])
# detect_sc
diff = c_frame_4sc.astype(np.int) - p_frame_4sc.astype(np.int)
if MAE(diff) >= self.sc_THRESH:
ap2([my_cnt, 1])
else:
ap2([my_cnt,0])
my_cnt += 1
empty = 0
else:
time.sleep(0.1)
empty += 1
pp1.join()
print('Process num:{} '.format(num), ' 予定フレーム:{}'.format(m - n + 1), ' 実際フレーム:{}'.format(len(result_logo)))
sc_log_path = tmp_dir + 'sc_{}.csv'.format(num)
logo_log_path = tmp_dir + 'logo_{}.csv'.format(num)
write_csv(logo_log_path, result_logo)
write_csv(sc_log_path, result_sc)
return
def detect_logo(self):
frame_num = self.count
s1 = time.time()
arr = np.array_split([i for i in range(frame_num)], self.threads)
args = [(self, arr[0], arr[-1], i) for i, arr in enumerate(arr)]
processs = []
for i in range(self.threads):
processs.append(Process(target=self.__class__.mt_f1, args=args[i]))
for th in processs:
th.start()
for th in processs:
th.join()
csv_files1 = sorted(glob.glob(tmp_dir + 'logo_[0-9].csv'))
list1 = join_csv_files(csv_files1)
write_csv(logo_log_path, list1)
csv_files2 = sorted(glob.glob(tmp_dir + 'sc_[0-9].csv'))
list2 = join_csv_files(csv_files2)
write_csv(sc_log_path, list2)
s2 = time.time()
print('End > analyze video , FPS={} ,'.format(
int(frame_num / (s2 - s1))), 'Time= {}sec'.format(int(s2 - s1)))
return
def main(self):
del_list = glob.glob(tmp_dir + '*.csv')
del_list.extend(glob.glob(tmp_dir + 'output.wav'))
for i in del_list:
os.remove(i)
p1 = Process(target=self.__class__.detect_mute, args=(self,))
p2 = Process(target=self.__class__.detect_logo, args=(self,))
jobs = [p1, p2]
for i in jobs:
i.start()
for j in jobs:
j.join()
return
def draw_csv(self,original=None):
if original=='y':
name=os.path.splitext(os.path.basename(a.name))[0]
img=result_image_dir + 'result_'+name+'.png'
else:
img=result_image_dir +'result.png'
sc=sc_log_path
logo=logo_log_path
mute=mute_log_path
x_detail=2
y_detail=2
print('drawing graph....')
if os.path.exists(img):
os.remove(img)
df_logo=np.loadtxt(logo,delimiter=',')
df_sc=np.loadtxt(sc,delimiter=',')
df_mute=np.loadtxt(mute,delimiter=',')
width = min(len(df_logo), len(df_sc), len(df_mute))
df_logo_y =df_logo[0:width][:,1]
df_sc_y =df_sc[0:width][:,1]
df_mute_y =df_mute[0:width][:,1]
xarr=[i for i in range(0,width)]
th=5000
xd=int(width/th)
fig=plt.figure(figsize=(16*x_detail, 8*y_detail), dpi=100)
ax = fig.add_subplot()
ax.set_xticks(np.linspace(0, th * (xd+1), xd+2),minor=False)
#ax.set_xticks(np.linspace(0, th * (xd+1) * (xd+1), 10*xd+11), minor=True)
#ax.grid(which = "minor", axis = "x", color = "black", alpha = 0.8,linestyle = "--", linewidth = 1)
ax.grid(which = "major", axis = "y", color = "orange", alpha = 0.8,linestyle = "-", linewidth = 1)
ax.set_yticks([0, 0.5, 1.0])
plt.plot(xarr, df_logo_y, color="Blue", label="logo")
plt.plot(xarr, df_mute_y,color="Red", label="mute")
plt.scatter(xarr, df_sc_y, color="Green", label="sc", marker=".")
ax.grid(True)
plt.xlabel('frame number')
plt.ylabel('match')
plt.legend()
plt.savefig(img, facecolor="skyblue", bbox_inches="tight")
print('drawing graph.... END!!!')
return
if __name__ == "__main__":
start = time.time()
video_file = str(r'video')
logo_path = str(r'logo') #jpgとかpngとかで与える、できれば二値変換しておく
a = analyze_ts(video_file, logo_path)
a.main()
a.draw_csv(original='y')
print(time.time() - start)